Demo MuleSoft-Integration-Architect-I Test | Latest MuleSoft-Integration-Architect-I Mock Test
Wiki Article
BONUS!!! Download part of Braindumpsqa MuleSoft-Integration-Architect-I dumps for free: https://drive.google.com/open?id=1mivbVrR3eG6pNXA5PO3B3PQKl5EsNFPP
When you have adequately prepared for the Salesforce Certified MuleSoft Integration Architect I (MuleSoft-Integration-Architect-I) questions, only then you become capable of passing the Salesforce exam. There is no purpose in attempting the Salesforce MuleSoft-Integration-Architect-I certification exam if you have not prepared with Braindumpsqa's Free Salesforce MuleSoft-Integration-Architect-I PDF Questions. It's time to get serious if you want to validate your abilities and earn the Salesforce MuleSoft-Integration-Architect-I Certification. If you hope to pass the Salesforce Certified MuleSoft Integration Architect I exam on your first attempt, you must be studied with real MuleSoft-Integration-Architect-I exam questions verified by Salesforce MuleSoft-Integration-Architect-I.
Salesforce MuleSoft-Integration-Architect-I Exam Syllabus Topics:
| Topic | Details |
|---|---|
| Topic 1 |
|
| Topic 2 |
|
| Topic 3 |
|
| Topic 4 |
|
| Topic 5 |
|
| Topic 6 |
|
>> Demo MuleSoft-Integration-Architect-I Test <<
Latest MuleSoft-Integration-Architect-I Mock Test, MuleSoft-Integration-Architect-I Reliable Exam Online
If only you provide the scanning copy of the MuleSoft-Integration-Architect-I failure marks we will refund you immediately. If you have any doubts about the refund or there are any problems happening in the process of refund you can contact us by mails or contact our online customer service personnel and we will reply and solve your doubts or questions timely. We provide the best service and MuleSoft-Integration-Architect-I Test Torrent to you to make you pass the exam fluently but if you fail in we will refund you in full and we won’t let your money and time be wasted. Our questions and answers are based on the real exam and conform to the popular trend in the industry.
Salesforce Certified MuleSoft Integration Architect I Sample Questions (Q193-Q198):
NEW QUESTION # 193
Cloud Hub is an example of which cloud computing service model?
- A. Platform as a Service (PaaS)
- B. Infrastructure as a Service (laaS)
- C. Software as a Service (SaaS)
- D. Monitoring as a Service (MaaS)
Answer: A
NEW QUESTION # 194
Which Exchange asset type represents configuration modules that extend the functionality of an API and enforce capabilities such as security?
- A. RESTAPIs
- B. Connectors
- C. Policies
- D. Rulesets
Answer: C
Explanation:
In Anypoint Exchange, policies are the asset type that represents configuration modules extending the functionality of an API and enforcing capabilities such as security. Policies can be applied to APIs to control access, apply throttling, manage security, and other aspects that modify or extend the behavior of APIs.
Rulesets, REST APIs, and connectors serve different purposes within the Anypoint Platform. Rulesets are used for validation or routing decisions. REST APIs define the endpoints and methods for API interactions, and connectors enable connectivity to various systems and services. Only policies are specifically designed to enforce additional capabilities on APIs.
References
* MuleSoft Anypoint Platform Documentation on API Policies
* Anypoint Exchange Overview
NEW QUESTION # 195
An Order microservice and a Fulfillment microservice are being designed to communicate with their dients through message-based integration (and NOT through API invocations).
The Order microservice publishes an Order message (a kind of command message) containing the details of an order to be fulfilled. The intention is that Order messages are only consumed by one Mute application, the Fulfillment microservice.
The Fulfilment microservice consumes Order messages, fulfills the order described therein, and then publishes an OrderFulfilted message (a kind of event message). Each OrderFulfilted message can be consumed by any interested Mule application, and the Order microservice is one such Mute application.
What is the most appropriate choice of message broker(s) and message destination(s) in this scenario?
- A. Order messages are sent to an Anypoint MQ exchange OrderFulfilled messages are sent to an Anypoint MQ queue Both microservices interact with Anypoint MQ as the message broker, which must therefore scale to support the load of both microservices
- B. Order messages are sent to a JMS queue. OrderFulfilled messages are sent to a JMS topic Both microservices interact with the same JMS provider (message broker) instance, which must therefore scale to support the load of both microservices
- C. Order messages are sent to a JMS queue. OrderFulfilled messages are sent to a JMS topic The Order microservice interacts with one JMS provider (message broker) and the Fulfillment microservice interacts with a different JMS provider, so that both message brokers can be chosen and scaled to best support the load of each microservice
- D. Order messages are sent directly to the Fulfillment microservices. OrderFulfilled messages are sent directly to the Order microservice The Order microservice interacts with one AMQP-compatible message broker and the Fulfillment microservice interacts with a different AMQP-compatible message broker, so that both message brokers can be chosen and scaled to best support the load of each microservice
Answer: B
Explanation:
* If you need to scale a JMS provider/ message broker, - add nodes to scale it horizontally or - add memory to scale it vertically * Cons of adding another JMS provider/ message broker: - adds cost. - adds complexity to use two JMS brokers - adds Operational overhead if we use two brokers, say, ActiveMQ and IBM MQ * So Two options that mention to use two brokers are not best choice. * It's mentioned that "The Fulfillment microservice consumes Order messages, fulfills the order described therein, and then publishes an OrderFulfilled message. Each OrderFulfilled message can be consumed by any interested Mule application." - When you publish a message on a topic, it goes to all the subscribers who are interested - so zero to many subscribers will receive a copy of the message. - When you send a message on a queue, it will be received by exactly one consumer. * As we need multiple consumers to consume the message below option is not valid choice: "Order messages are sent to an Anypoint MQ exchange. OrderFulfilled messages are sent to an Anypoint MQ queue. Both microservices interact with Anypoint MQ as the message broker, which must therefore scale to support the load of both microservices" * Order messages are only consumed by one Mule application, the Fulfillment microservice, so we will publish it on queue and OrderFulfilled message can be consumed by any interested Mule application so it need to be published on Topic using same broker. * answer: Best choice in this scenario is: "Order messages are sent to a JMS queue. OrderFulfilled messages are sent to a JMS topic. Both microservices interact with the same JMS provider (message broker) instance, which must therefore scale to support the load of both microservices" Tried to depict scenario in diagram:
Diagram Description automatically generated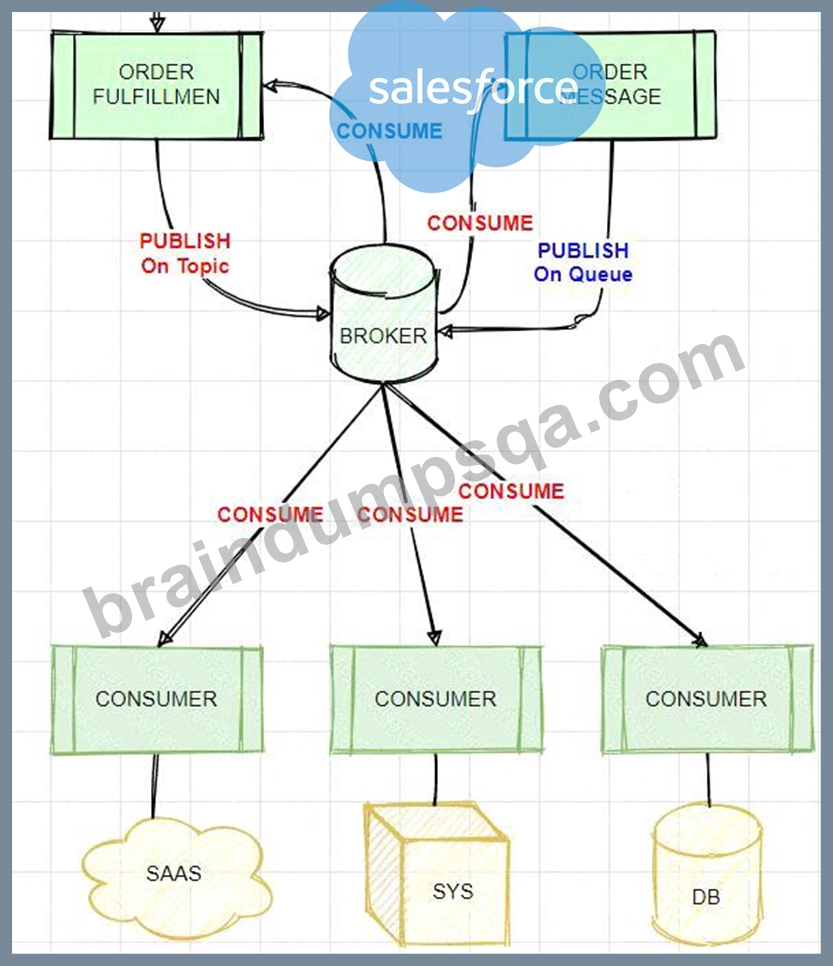
NEW QUESTION # 196
Refer to the exhibit.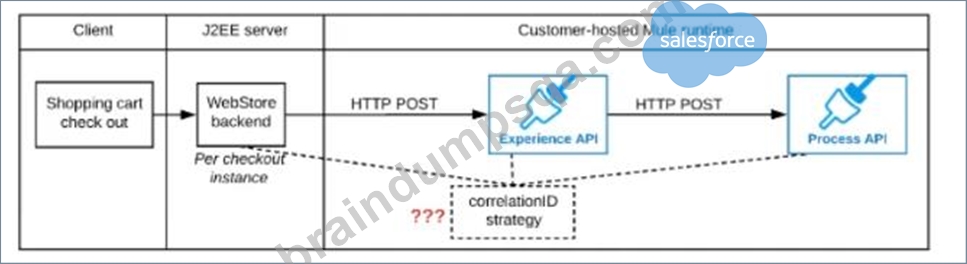
A shopping cart checkout process consists of a web store backend sending a sequence of API invocations to an Experience API, which in turn invokes a Process API. All API invocations are over HTTPS POST. The Java web store backend executes in a Java EE application server, while all API implementations are Mule applications executing in a customer -hosted Mule runtime.
End-to-end correlation of all HTTP requests and responses belonging to each individual checkout Instance is required. This is to be done through a common correlation ID, so that all log entries written by the web store backend, Experience API implementation, and Process API implementation include the same correlation ID for all requests and responses belonging to the same checkout instance.
What is the most efficient way (using the least amount of custom coding or configuration) for the web store backend and the implementations of the Experience API and Process API to participate in end-to-end correlation of the API invocations for each checkout instance?
A)
The web store backend, being a Java EE application, automatically makes use of the thread-local correlation ID generated by the Java EE application server and automatically transmits that to the Experience API using HTTP-standard headers No special code or configuration is included in the web store backend, Experience API, and Process API implementations to generate and manage the correlation ID
B)
The web store backend generates a new correlation ID value at the start of checkout and sets it on the X-CORRELATlON-lt HTTP request header In each API invocation belonging to that checkout No special code or configuration is included in the Experience API and Process API implementations to generate and manage the correlation ID
C)
The Experience API implementation generates a correlation ID for each incoming HTTP request and passes it to the web store backend in the HTTP response, which includes it in all subsequent API invocations to the Experience API.
The Experience API implementation must be coded to also propagate the correlation ID to the Process API in a suitable HTTP request header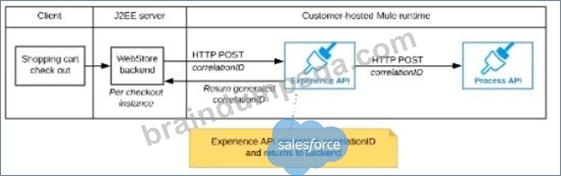
D)
The web store backend sends a correlation ID value in the HTTP request body In the way required by the Experience API The Experience API and Process API implementations must be coded to receive the custom correlation ID In the HTTP requests and propagate It in suitable HTTP request headers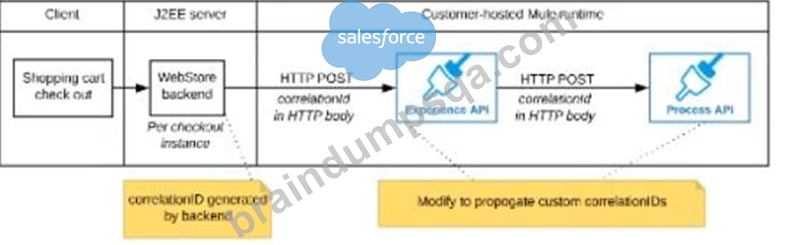
- A. Option A
- B. Option D
- C. Option C
- D. Option B
Answer: D
Explanation:
Correct answer is "The web store backend generates a new correlation ID value at the start of checkout and sets it on the X-CORRELATION-ID HTTP request header in each API invocation belonging to that checkout No special code or configuration is included in the Experience API and Process API implementations to generate and manage the correlation ID" : By design, Correlation Ids cannot be changed within a flow in Mule 4 applications and can be set only at source. This ID is part of the Event Context and is generated as soon as the message is received by the application. When a HTTP Request is received, the request is inspected for "X-Correlation-Id" header. If "X-Correlation-Id" header is present, HTTP connector uses this as the Correlation Id. If "X-Correlation-Id" header is NOT present, a Correlation Id is randomly generated. For Incoming HTTP Requests: In order to set a custom Correlation Id, the client invoking the HTTP request must set "X-Correlation-Id" header. This will ensure that the Mule Flow uses this Correlation Id. For Outgoing HTTP Requests: You can also propagate the existing Correlation Id to downstream APIs. By default, all outgoing HTTP Requests send "X-Correlation-Id" header. However, you can choose to set a different value to "X-Correlation-Id" header or set "Send Correlation Id" to NEVER.
Mulesoft Reference: https://help.mulesoft.com/s/article/How-to-Set-Custom-Correlation-Id-for-Flows-with-HTTP-Endpoint-in-Mule-4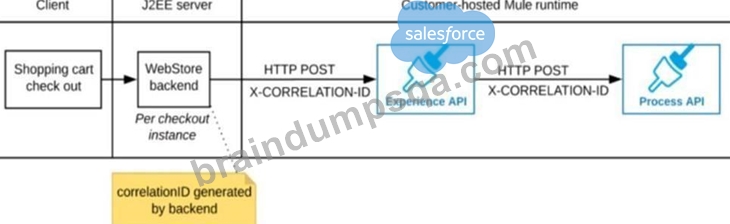
NEW QUESTION # 197
Refer to the exhibit.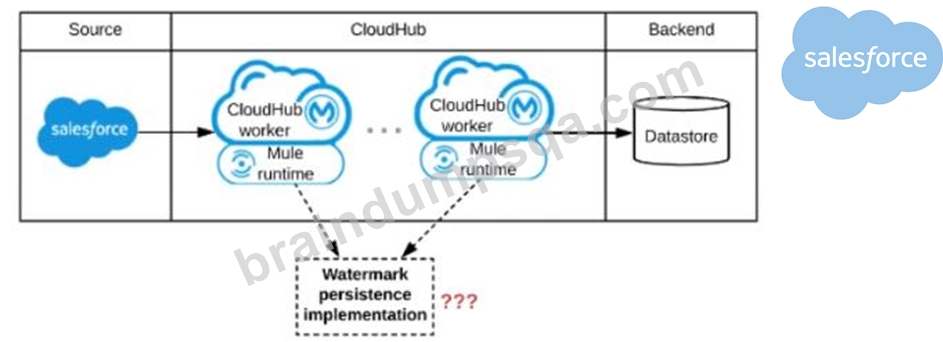
A Mule application is being designed to be deployed to several CIoudHub workers. The Mule application's integration logic is to replicate changed Accounts from Satesforce to a backend system every 5 minutes.
A watermark will be used to only retrieve those Satesforce Accounts that have been modified since the last time the integration logic ran.
What is the most appropriate way to implement persistence for the watermark in order to support the required data replication integration logic?
- A. Persistent Object Store
- B. Persistent Cache Scope
- C. Persistent VM Queue
- D. Persistent Anypoint MQ Queue
Answer: A
Explanation:
* An object store is a facility for storing objects in or across Mule applications. Mule uses object stores to persist data for eventual retrieval.
* Mule provides two types of object stores:
1) In-memory store - stores objects in local Mule runtime memory. Objects are lost on shutdown of the Mule runtime.
2) Persistent store - Mule persists data when an object store is explicitly configured to be persistent.
In a standalone Mule runtime, Mule creates a default persistent store in the file system. If you do not specify an object store, the default persistent object store is used.
MuleSoft Reference: https://docs.mulesoft.com/mule-runtime/3.9/mule-object-stores
NEW QUESTION # 198
......
The Salesforce Certified MuleSoft Integration Architect I (MuleSoft-Integration-Architect-I) practice exam consists of a Salesforce Certified MuleSoft Integration Architect I (MuleSoft-Integration-Architect-I) PDF dumps format, Desktop-based MuleSoft-Integration-Architect-I practice test software and a Web-based Salesforce Certified MuleSoft Integration Architect I (MuleSoft-Integration-Architect-I) practice exam. Each of the Braindumpsqa Salesforce MuleSoft-Integration-Architect-I Exam Dumps formats excels in its way and carries actual Salesforce Certified MuleSoft Integration Architect I (MuleSoft-Integration-Architect-I) exam questions for optimal preparation.
Latest MuleSoft-Integration-Architect-I Mock Test: https://www.braindumpsqa.com/MuleSoft-Integration-Architect-I_braindumps.html
- Valid MuleSoft-Integration-Architect-I Dumps Demo ???? Latest MuleSoft-Integration-Architect-I Braindumps Free ???? MuleSoft-Integration-Architect-I Latest Guide Files ???? Copy URL ▛ www.prepawaypdf.com ▟ open and search for ➽ MuleSoft-Integration-Architect-I ???? to download for free ????100% MuleSoft-Integration-Architect-I Correct Answers
- MuleSoft-Integration-Architect-I Test Braindumps ???? Accurate MuleSoft-Integration-Architect-I Study Material ⏰ MuleSoft-Integration-Architect-I Practice Test Engine ✊ Search for ➠ MuleSoft-Integration-Architect-I ???? and easily obtain a free download on ▷ www.pdfvce.com ◁ ????MuleSoft-Integration-Architect-I Official Practice Test
- Related MuleSoft-Integration-Architect-I Certifications ???? Latest MuleSoft-Integration-Architect-I Braindumps Free ???? MuleSoft-Integration-Architect-I Reliable Test Topics ???? Open website ▶ www.pdfdumps.com ◀ and search for { MuleSoft-Integration-Architect-I } for free download ????MuleSoft-Integration-Architect-I Certification Exam Infor
- 2026 Salesforce MuleSoft-Integration-Architect-I: Salesforce Certified MuleSoft Integration Architect I Latest Demo Test ???? Open 《 www.pdfvce.com 》 and search for ⇛ MuleSoft-Integration-Architect-I ⇚ to download exam materials for free ????Dumps MuleSoft-Integration-Architect-I Guide
- MuleSoft-Integration-Architect-I Exam Simulator Fee ???? Related MuleSoft-Integration-Architect-I Certifications ???? MuleSoft-Integration-Architect-I Reliable Test Forum ???? Immediately open 「 www.troytecdumps.com 」 and search for “ MuleSoft-Integration-Architect-I ” to obtain a free download ????Valid MuleSoft-Integration-Architect-I Dumps Demo
- Pass-Sure Demo MuleSoft-Integration-Architect-I Test offer you accurate Latest Mock Test | Salesforce Salesforce Certified MuleSoft Integration Architect I ???? Search for ☀ MuleSoft-Integration-Architect-I ️☀️ and download it for free immediately on 【 www.pdfvce.com 】 ????100% MuleSoft-Integration-Architect-I Correct Answers
- MuleSoft-Integration-Architect-I Exam Price ???? MuleSoft-Integration-Architect-I Practice Test Engine ???? MuleSoft-Integration-Architect-I Exam Price ???? ➽ www.exam4labs.com ???? is best website to obtain ➽ MuleSoft-Integration-Architect-I ???? for free download ????Accurate MuleSoft-Integration-Architect-I Study Material
- MuleSoft-Integration-Architect-I Exam Training Programs - MuleSoft-Integration-Architect-I Latest Test Sample - MuleSoft-Integration-Architect-I Valid Test Questions ???? Open website ➽ www.pdfvce.com ???? and search for ➽ MuleSoft-Integration-Architect-I ???? for free download ????Related MuleSoft-Integration-Architect-I Certifications
- MuleSoft-Integration-Architect-I Reliable Test Topics ???? MuleSoft-Integration-Architect-I Latest Guide Files ➕ MuleSoft-Integration-Architect-I Exams Torrent ???? Open website ( www.prep4sures.top ) and search for ( MuleSoft-Integration-Architect-I ) for free download ☣MuleSoft-Integration-Architect-I Exam Simulator Fee
- Latest MuleSoft-Integration-Architect-I Exam Objectives ???? Latest MuleSoft-Integration-Architect-I Exam Objectives ???? Related MuleSoft-Integration-Architect-I Certifications ???? Enter ▛ www.pdfvce.com ▟ and search for ➽ MuleSoft-Integration-Architect-I ???? to download for free ????MuleSoft-Integration-Architect-I Certification Exam Infor
- 100% Pass 2026 Updated Salesforce MuleSoft-Integration-Architect-I: Demo Salesforce Certified MuleSoft Integration Architect I Test ???? Open ▶ www.exam4labs.com ◀ enter ☀ MuleSoft-Integration-Architect-I ️☀️ and obtain a free download ????MuleSoft-Integration-Architect-I Test Braindumps
- roxannpzcx575508.azzablog.com, mariamzbwq609708.life3dblog.com, asiyaqgpo880034.dekaronwiki.com, royonpn717686.lotrlegendswiki.com, antonzuax481368.wikidank.com, finnianjhpk316662.wikibyby.com, aronvtlx293643.thenerdsblog.com, anitassyf667094.nico-wiki.com, friendlybookmark.com, www.stes.tyc.edu.tw, Disposable vapes
P.S. Free & New MuleSoft-Integration-Architect-I dumps are available on Google Drive shared by Braindumpsqa: https://drive.google.com/open?id=1mivbVrR3eG6pNXA5PO3B3PQKl5EsNFPP
Report this wiki page